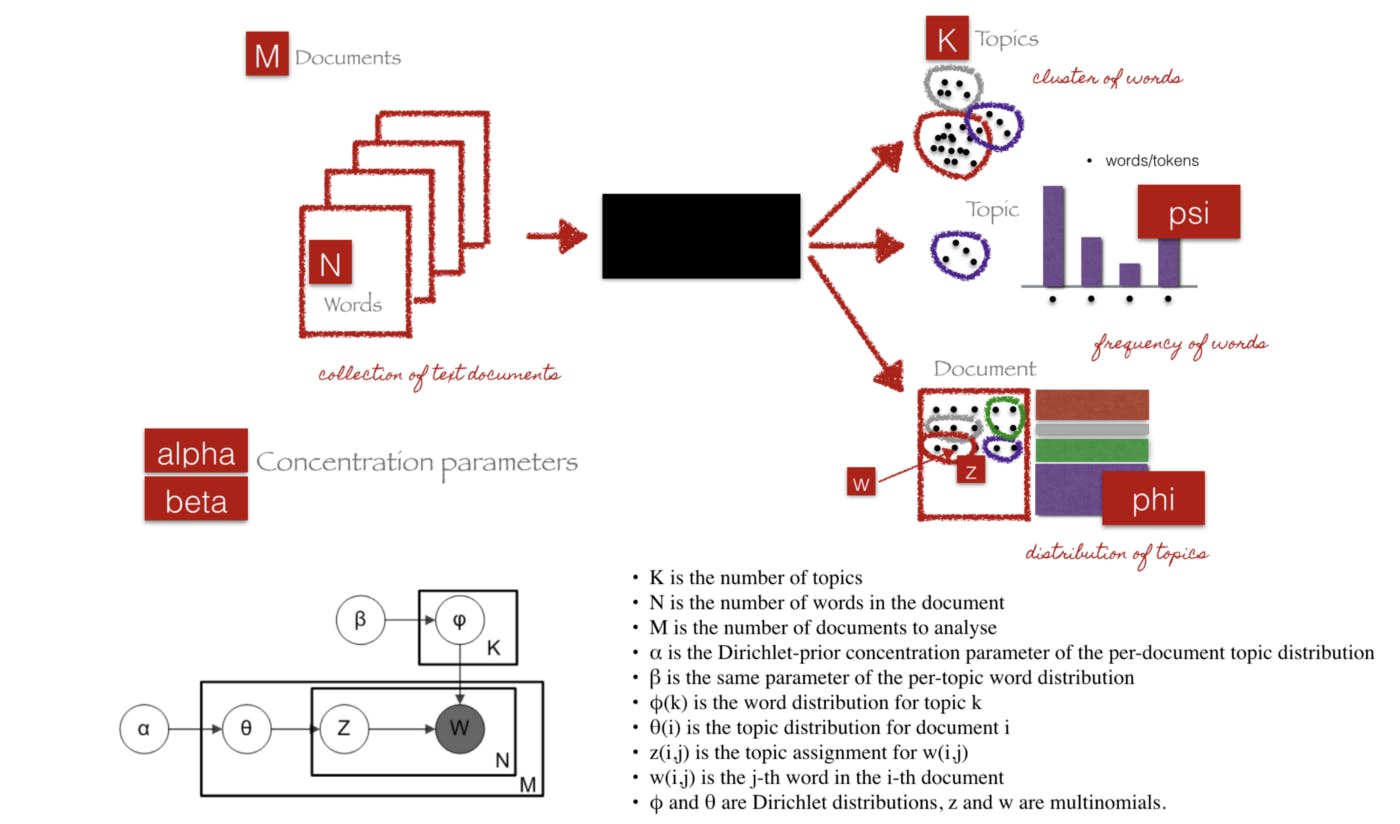
Topic Modelling


It is said that over 2.5 quadrillions of data are being generated every second and obviously over time, it will become difficult to access the data. We apparently need tools to help us organise, search and digest quality information.
Topic modelling aids us to comprehend and extract useful insight from Large textual data, also it helps to find a group of the word(topic) from a document.
It is also useful in:
- Finding a topic that is present in a document or corpus
- Segmenting document according to these topics
- Searching, organising and summarizing text
There are lot of technique for topic model, we will talk about LDA, and ETM
Latent Dirichlet Allocation (LDA):
LDA is an unsupervised learning algorithm that assumes that each document was generated by picking a set of topics and then for each topic, picking a set of word.
LDA sight document as Bag of word (order don't matter)
For example:
If we have:
- Document 1: Data is an important asset to the business
- Document 2: In section 2 of the constitution, no one is above the law
- Document 3: It's important for a business to create marketing strategies
- Document 4: The Nigeria Government withdraw $123Million from IMF
- Document 5: Cat and Dog are enemies
The LDA extract topics from the document and how much each topic are represented in a document (probability of the topic)
Example 1
Topic 1: 40% Business, 20% Data, 20% Asset, 10% Marketing ...... we can say this fall under business
Topic 2: 30% Government, 30% constitution, 10% Nigeria.......We can say this fall under Government
Topic 3: 40% Cat, 40% Dog, 20% Enemies... let's say this fall under Pet
Document:
Document 1 and 3: 100% Topic 1
Document 2 and 4: 100% Topic 2
Document 5: 100% Topic 3
Let's see how LDA works:

LDA use "Collapsed Gibbs or Poisson sampling" to learning the topic and topic representation of each document.
- Randomly assign each word in the document to one of the K topics
- Randomly assign topic representation of the documents and word distributions of all the topics So, therefore,
For each document d go through each word w and compute:
- t = Topic
- d = Document
- w = Word
p(t | d): symmetry of words in *d* that are assigned to *t*
p(w | t): assign *t* over all *d* that comes from *w*
Reassign W a new T where we choose T with probability
p(t | d) * p(w | t’)
This generative model predicts the probability that the topic generated word
The LDA model train to output;
- psi, the distribution of words for each topic t
- phi, the distribution of topics for each document i
On iterating the last step, we reach a stable state where topic assignments or allocations are great. This will be great for determining the topic mixture of each document.
Click here to see a notebook file on using LDA and LDA with Genism. In this example, we used BBC Africa eyes dataset.
LDA is an amazing technique but has a lot of disadvantage when working with large vocabulary document, as practitioners have to prune their document to make a good model. This birth to a new technique called ETM (Embedded topic modelling).
Embedded Topic Modelling
ETM also know as embedded topic modelling is a probabilistic semantics model, that provides a low dimensional representation of the meaning of a word, each term is a represented by an embedded, each topic is a point in that embedding space and the topic distribution is proportional.
ETM is also great in the presence of stop words, unlike most common topic models. When stop words are included in the vocabulary, the ETM assigns topics to the corresponding area of the embedding space
One great advantage of ETM is that it incorporates word similarity to topic model and its built on two main ideas, LDA and Word Embedding.
What ETM does?
The ETM is a topic model that uses embedding representations of both words and topics, it embeds the vocabulary in an L Dimensional space. These embeddings are similar to classical word embedding secondly, it represents each document in K latent topics
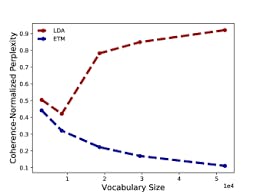
The diagram above shows the coherence of LDA and ETM, the dataset is a corpus of 11.2k articles from 20NewsGroup and for 100 topics.
The red line is LDA and the Blue is ETM. The performance of the red line (LDA) decline as the vocabulary size increases, the quality of topics and predictive performance get worse. The blue line (ETM) maintains a good performance as the quality of vocabulary increases.
D-ETM
D-ETM is a generative model that incorporates both D-LDA and ETM, it models each word as a categorical distribution with word embedding per time step embedding as the parameter.
Categorical distribution example: Count the number of text in a doc, the possible outcome of any word in that text is based on the probability of the number of word in the text.]
The D-ETM learn topic path by defining a random walk over embedded representation of the topic. We fit the D-ETM using structured amortized variational inference with a recurrent neural network.
The ETM is great at handling large dataset but it fails at handling document whose topic vary over time
How it works
The D-ETM uses embedding representations of words and topics, it embeds each topic at a given timestamp, unlike the traditional topic model where topics are distributed as a vocabulary.
In D-ETM, similar words are assigned to a similar topic, since the representation is close in the embedded space, it also, enforces smooth variations of the topics by using a Markov chain.
DETM basically helps in finding the evolution of topics over time k
Additional resources